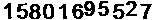
作為現代的計算機科學和人工智能領域的重要技術分支,自然語言處理涉及到了語言學,數學,和計算機科學。自然語言處理和語言學的研究對象一樣是自然語言,但是其側重點在于自然語言通信計算機系統的實現,屬于計算機科學研究范疇。同時,鑒于其研究過程中需要運用來自外界的知識,自然語言處理也被認為是解決人工智能的研究核心。
在應用層面,自然語言處理是企業和開發者用于文本分析和挖掘的工具,現在已經在電商、金融、物流、文化娛樂等行業中得到應用。自然語言處理能夠實現搭建內容搜索、內容推薦、輿情識別及分析、文本結構化、對話機器人等智能產品,也能根據具體的使用場景為公司實現個性化方案定制。
但是在實際運用中,多數自然語言處理軟件也面臨著一些局限性。待處理的語料庫知識資源存在數據泄漏的隱患 大部分研究者的語料庫都是耗費了大量人力物力收集整理的,價值密度極高, 甚至是畢生的心血積累。而目前自然語言處理的機構大部分提供的都是自然語言 處理云服務平臺,要求使用者上傳待處理的語料庫,如騰訊自然語言處理云服務、百度 自然語言處理云服務。云端存儲的數據資源脫離了上傳者后,數據確權上沒有法律保障, 存在數據泄露并被竊取濫用的巨大隱患,導致大部分使用者望而卻步。
NLPIR-Parser歷時 20余年,為一般用戶提供了本地化部署的客戶端實現語義智能分析的全鏈條一站 式服務,也為軟件工程師提供了二次開發接口。NLPIR-Parser平臺包含精準采集, 文檔格式轉換、新詞發現、批量分詞、語言統計、文本聚類、文本分類、摘要實體、智能過濾、情感分析、文檔去重、全文檢索和編碼轉換十三項獨立功能,涵 蓋了從數據的采集預處理、自然語言處理到文本挖掘、信息檢索再到可視化呈現、 結果導出等全鏈條各個環節的語義分析工具。
|